Rest API Pattern - Golang

Software Engineer
The most comfortable and effective from the point of view of system design is Design first pattern.
Starting review the different approaches base on what I have seen.
To tell about advantages and disadvantages and to solve one unpleasant problem in one of variety cases.

gRPC allows you to organise contracts well out of the box.
Design first pattern is already implemented by the approach itself. main thing for organise one big repository with common service api and develop standards within the team. Versioning, documentation and naming in a single place. On the downside, the business needs to invest in code generation, maintenance and usability.
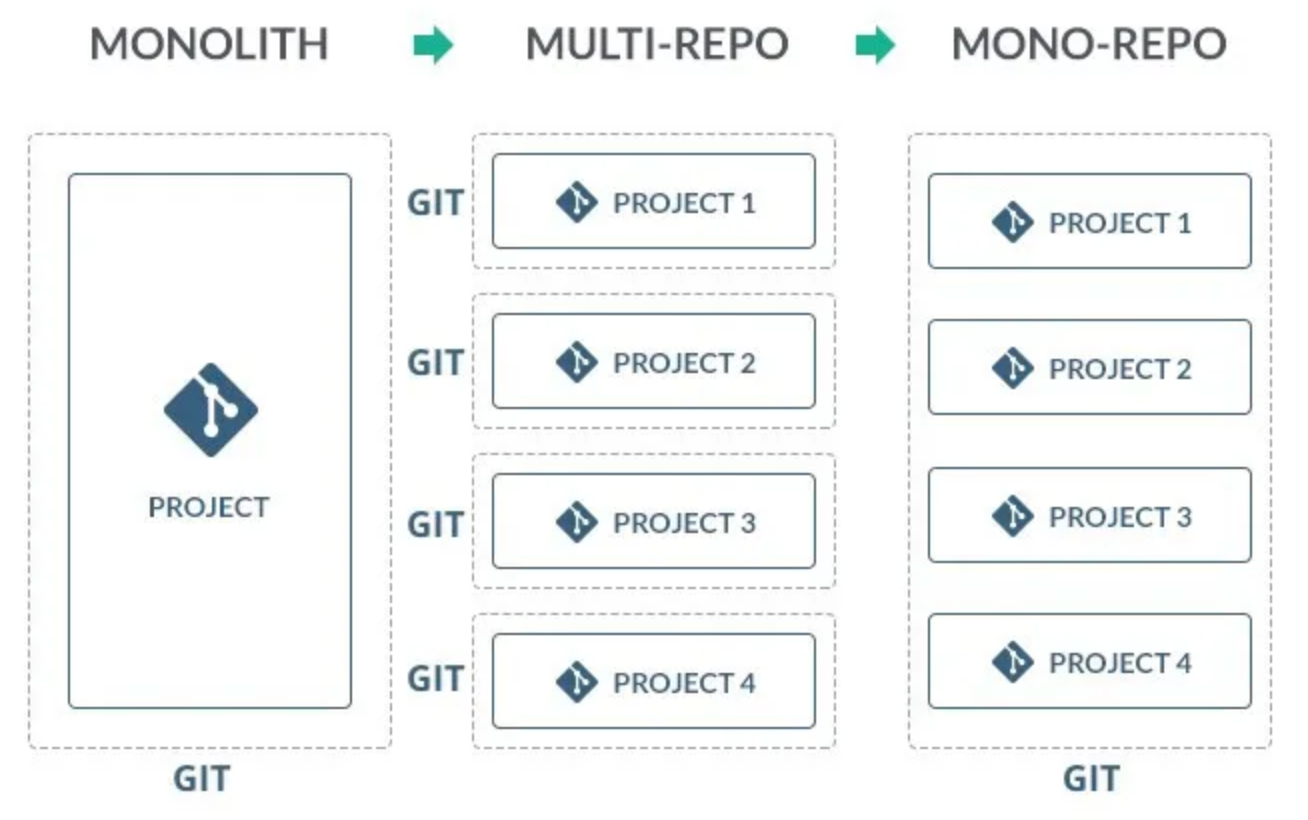
Multiple microservices around a monolith in a monorepository is another case.
Just as convenient. Usually a microservice appears next to a monolith when you need to do a finite and isolated task. Microservices on go are written quickly, sometimes http server in single main implementation is enough to quickly run some mvp. At the same time it is convenient to place the server client inside the same package. Everything is perfectly and quickly covered by tests using httptest. The headache here is mainly for the devops team, that would organise the deploy, as well as competently build within the team the correct work with the monorepository. Monorepository vs. multirepository ancient holywar)
In a classic microservice architecture based on synchronous http REST interactions between individual services, you can organise the logic of placing servers and their clients differently.
In general, if your system has a lot of synchronous interactions, then I have bad news for you. Perhaps you are a happy owner of a distributed monolith. How to deal with it is a separate story.
The first approach is to implement Design First codegeneration. First we describe the openAPI/swagger contract. On the basis of this we build a billet in which we already implement from top to bottom all the necessary logic. It is perfect for companies that have come to unified templates for microservices. Where new services appear frequently and this process is well established. The advantages are the same as in the process of protobuf description. Minuses — exactly the same) Great efforts of the development team are spent on creation and support of the code generation system.

Here is a good article on this topic
Swagger and OpenAPI have their own libraries for code generation too.
On the other hand — it may be inefficient to use the swagger separately.
I’ve seen a lot of dead swaggers.
Swagger becomes useless as soon as it is no longer supported. What would it take to use it effectively outside of a Design First approach. For answering a few questions: Where will it be stored? Who will be responsible for it? What do you need to know and be able to update it? What do you need to do to roll back to a previous version? What happens if we change it in the code but not in the contract?
Cheap and practical, it came in handy more than once.
Especially after half a year, when asked to take into account some ancient business logic.
There was another problem. The release of any changes in the contract was long and very tedious. Making changes to the server. Push changes. Go to the repository. Test the stable version. Roll out a tag. Make the same changes to the client. Push changes. Go to another repository. Roll out another tag. Every time when u want to add veryImportantBytes to the system contract…
Another annoyance — transport layer models are duplicated in server and client.
The way out was not so complicated and solved several problems at once.
As in the monorep case — place the client next to the server.
Now I’ll tell you how to do it neatly in go:
For example got very early for starting build rest-api http server: https://github.com/redhaanggara21/redha-rgb-golang-test
https://github.com/redhaanggara21/redha-rgb-golang-test
This example does not pay close attention to naming or technical implementation details. Only the usecase of the multimodule repository and the client’s location near the server.
Here is project structure:

And client code:
package server
import (
"bytes"
"encoding/json"
"errors"
"fmt"
"io"
"net/http"
)
var (
emptyRequestError = errors.New("empty request")
)
type client struct {
BaseURL string
*http.Client
}
func NewClient(baseUrl string) *client {
c := &http.Client{} return &client{
BaseURL: baseUrl,
Client: c,
}
}
func (c *client) V1MethodPost(dto *RequestDTO) (*ResponseDTO, error) {
if dto == nil {
return nil, emptyRequestError
} payloadBuf := new(bytes.Buffer)
err := json.NewEncoder(payloadBuf).Encode(dto)
if err != nil {
return nil, fmt.Errorf("failed encode data V1Method from API Server: %v", err)
} res, err := c.Post(c.BaseURL, "application/json", payloadBuf)
if err != nil {
return nil, err
}
defer res.Body.Close() data, err := io.ReadAll(res.Body)
if err != nil {
return nil, fmt.Errorf("failed ReadAll body response V1Method from API Server: %v", err)
} if res.StatusCode != http.StatusOK {
if res.StatusCode == http.StatusNoContent {
return nil, nil
} return nil, fmt.Errorf(`not success status V1Method from API Server.
Actual status: %d\nBody response: %s`, res.StatusCode, string(data))
} result := &ResponseDTO{} if err = json.Unmarshal(data, &result); err != nil {
return nil, fmt.Errorf("failed decode response V1Method from API Server: %v", err)
} return result, err
}
Server — abstract name of the microservice for which we write a client. It can be for example order order service. then the naming in the place of use will be order.NewClient(baseUrl)
We need use go mod init inside client directory.
Then make tag with naming like pkg/server/v0.0.0.
Then go mod edit -replace github.com/redhaanggara21/golang-gin/pkg/server=../pkg/server
Now you have got server and client in the single repo.
http transport logic incapsulated into client.
You can write tests client -> transport server layer unit using httptest.
And man advantage — single place for DTO structs. Server and involved microservices using same dependency with its own versioning.
You can import othe module like this:

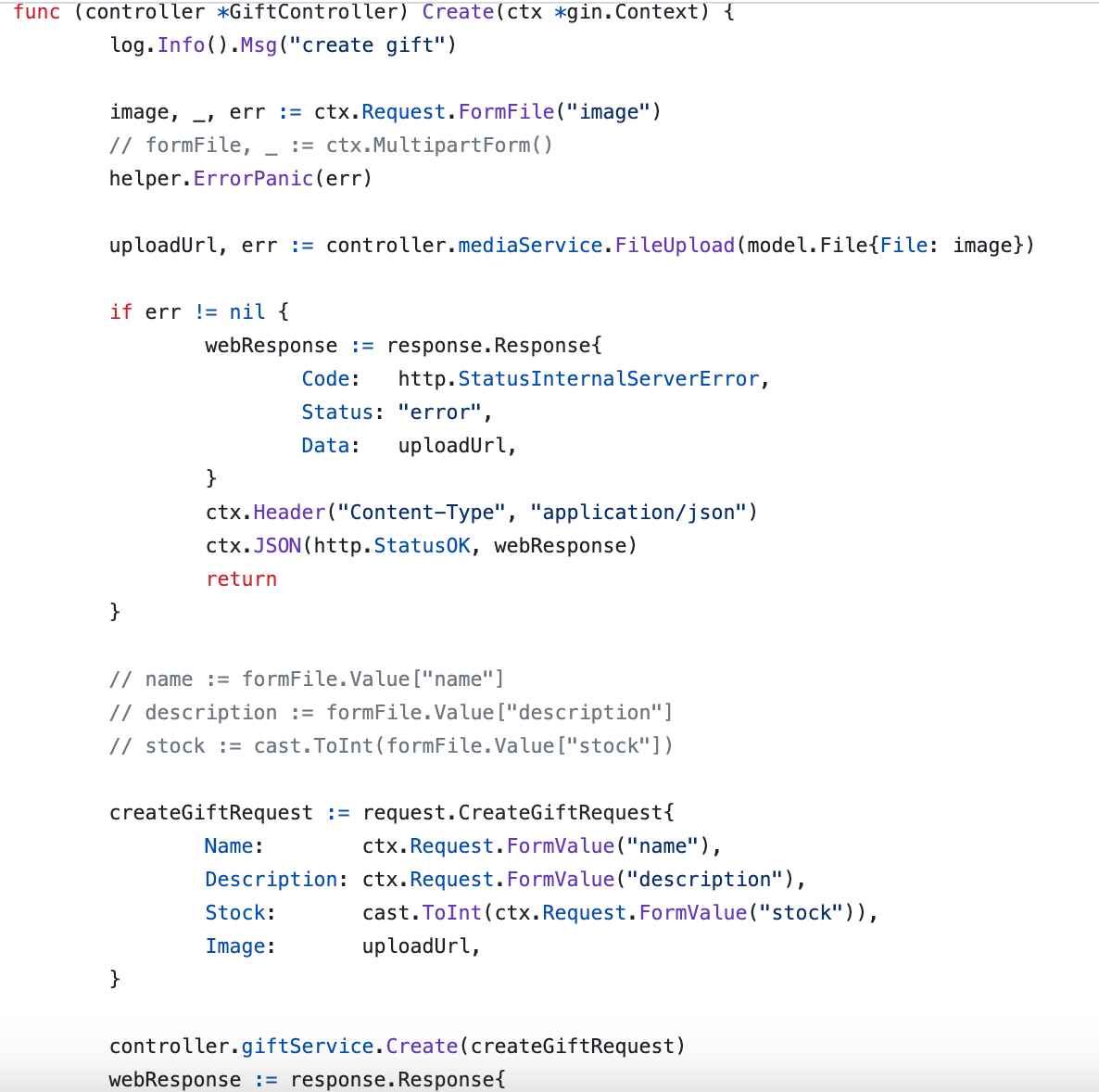
Disadvantages:
go test ./… from the root now dont work with submodules. You should manual write into gitCI.
Your team should agree and remember that the client requires its own way and order of naming tags. Of course you can automate this.
To summarise — there are no perfect approaches.
Especially since legacy can force sometimes making calculate weigh and height for wiritng the pros and cons. It seems to me that the idea of design first pattern pays off in the long run when building distributed systems. (Let’s strive to write good code)




