Pipeline Apache Flink, Kafka, Postgres, Elasticsearch, Kibana For Real-Time Streaming
Building Real-Time Data Streaming Pipeline using Apache Flink, Kafka, Postgres, Elasticsearch, Kibana


Introduction
Before diving into the integration, let’s briefly understand what each component offers:
Apache Kafka: A distributed streaming platform that excels in publishing and subscribing to streams of records, storing these records, and processing them as they occur.
Apache Flink: A framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink is known for its high throughput and low-latency streaming capabilities.
PostgreSQL (Postgres): A powerful, open-source object-relational database system known for its reliability, feature robustness, and performance.
Elasticsearch: A distributed, RESTful search and analytics engine capable of addressing a growing number of use cases.
Kibana: A data visualization dashboard for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster.
Architectural Overview
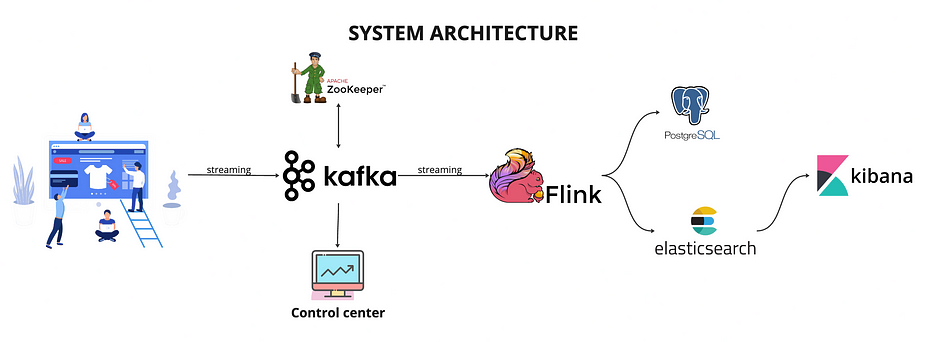
Within integrated architecture:
Data Ingestion: Data is ingested in real-time through Apache Kafka, which acts as the initial entry point for streaming data.
Stream Processing: Apache Flink processes the streaming data, performing tasks such as aggregations, enrichments, or complex computations.
Data Storage and Indexing: Processed data
Prerequisites
Apache Kafka: An open-source stream processing platform that facilitates the building of real-time data pipelines and streaming applications.
Apache Flink: A distributed stream processing framework that enables powerful analytics and event-driven applications.
Postgres: A powerful, open-source relational database management system.
Step 1: Postgres Schema
Start by creating a weather table sql file, so that when the container comes up, it executes the below mentioned sql file and creates a table inside postgres container.
CREATE TABLE weather (
id SERIAL PRIMARY KEY,
city VARCHAR (255) NOT NULL,
average_temperature DOUBLE PRECISION
);
Step 2: Dockerfile for Postgres container
This Dockerfile path will be mentioned inside docker-compose.yml file.
FROM postgres:latest
COPY create_table.sql /docker-entrypoint-initdb.d/
Step 3: Setting up Kafka Python Producer
Create a new folder named kafka-producer and add a python script which will run infinitely inside the docker container.sasa
import datetime
import time
import random
import schedule
from json import dumps
from faker import Faker
from kafka import KafkaProducer
kafka_nodes = "kafka:9092"
myTopic = "weather"
def gen_data():
faker = Faker()
prod = KafkaProducer(bootstrap_servers=kafka_nodes, value_serializer=lambda x:dumps(x).encode('utf-8'))
my_data = {'city': faker.city(), 'temperature': random.uniform(10.0, 110.0)}
print(my_data)
prod.send(topic=myTopic, value=my_data)
prod.flush()
if __name__ == "__main__":
gen_data()
schedule.every(10).seconds.do(gen_data)
while True:
schedule.run_pending()
time.sleep(0.5)
The above file runs periodically to generate (city, temperature) pair and produces it to the Kafka topic weather.
Step 4: Adding Depedency and wait-for-it.sh
So, from a precautionary perspective, I like to add a file called wait-for-it.sh which basically waits for Kafka and zookeeper broker to come up before we start producing message to the topic. This in turn helps us in avoiding any unwanted exception that can take place during runtime.
#!/usr/bin/env bash
# Use this script to test if a given TCP host/port are available
cmdname=$(basename $0)
echoerr() { if [[ $QUIET -ne 1 ]]; then echo "$@" 1>&2; fi }
usage()
{
cat << USAGE >&2
Usage:
$cmdname host:port [-s] [-t timeout] [-- command args]
-h HOST | --host=HOST Host or IP under test
-p PORT | --port=PORT TCP port under test
Alternatively, you specify the host and port as host:port
-s | --strict Only execute subcommand if the test succeeds
-q | --quiet Don't output any status messages
-t TIMEOUT | --timeout=TIMEOUT
Timeout in seconds, zero for no timeout
-- COMMAND ARGS Execute command with args after the test finishes
USAGE
exit 1
}
wait_for()
{
if [[ $TIMEOUT -gt 0 ]]; then
echoerr "$cmdname: waiting $TIMEOUT seconds for $HOST:$PORT"
else
echoerr "$cmdname: waiting for $HOST:$PORT without a timeout"
fi
start_ts=$(date +%s)
while :
do
if [[ $ISBUSY -eq 1 ]]; then
nc -z $HOST $PORT
result=$?
else
(echo > /dev/tcp/$HOST/$PORT) >/dev/null 2>&1
result=$?
fi
if [[ $result -eq 0 ]]; then
end_ts=$(date +%s)
echoerr "$cmdname: $HOST:$PORT is available after $((end_ts - start_ts)) seconds"
break
fi
sleep 1
done
return $result
}
wait_for_wrapper()
{
# In order to support SIGINT during timeout: http://unix.stackexchange.com/a/57692
if [[ $QUIET -eq 1 ]]; then
timeout $BUSYTIMEFLAG $TIMEOUT $0 --quiet --child --host=$HOST --port=$PORT --timeout=$TIMEOUT &
else
timeout $BUSYTIMEFLAG $TIMEOUT $0 --child --host=$HOST --port=$PORT --timeout=$TIMEOUT &
fi
PID=$!
trap "kill -INT -$PID" INT
wait $PID
RESULT=$?
if [[ $RESULT -ne 0 ]]; then
echoerr "$cmdname: timeout occurred after waiting $TIMEOUT seconds for $HOST:$PORT"
fi
return $RESULT
}
# process arguments
while [[ $# -gt 0 ]]
do
case "$1" in
*:* )
hostport=(${1//:/ })
HOST=${hostport[0]}
PORT=${hostport[1]}
shift 1
;;
--child)
CHILD=1
shift 1
;;
-q | --quiet)
QUIET=1
shift 1
;;
-s | --strict)
STRICT=1
shift 1
;;
-h)
HOST="$2"
if [[ $HOST == "" ]]; then break; fi
shift 2
;;
--host=*)
HOST="${1#*=}"
shift 1
;;
-p)
PORT="$2"
if [[ $PORT == "" ]]; then break; fi
shift 2
;;
--port=*)
PORT="${1#*=}"
shift 1
;;
-t)
TIMEOUT="$2"
if [[ $TIMEOUT == "" ]]; then break; fi
shift 2
;;
--timeout=*)
TIMEOUT="${1#*=}"
shift 1
;;
--)
shift
CLI=("$@")
break
;;
--help)
usage
;;
*)
echoerr "Unknown argument: $1"
usage
;;
esac
done
if [[ "$HOST" == "" || "$PORT" == "" ]]; then
echoerr "Error: you need to provide a host and port to test."
usage
fi
TIMEOUT=${TIMEOUT:-15}
STRICT=${STRICT:-0}
CHILD=${CHILD:-0}
QUIET=${QUIET:-0}
# check to see if timeout is from busybox?
# check to see if timeout is from busybox?
TIMEOUT_PATH=$(realpath $(which timeout))
if [[ $TIMEOUT_PATH =~ "busybox" ]]; then
ISBUSY=1
BUSYTIMEFLAG="-t"
else
ISBUSY=0
BUSYTIMEFLAG=""
fi
if [[ $CHILD -gt 0 ]]; then
wait_for
RESULT=$?
exit $RESULT
else
if [[ $TIMEOUT -gt 0 ]]; then
wait_for_wrapper
RESULT=$?
else
wait_for
RESULT=$?
fi
fi
if [[ $CLI != "" ]]; then
if [[ $RESULT -ne 0 && $STRICT -eq 1 ]]; then
echoerr "$cmdname: strict mode, refusing to execute subprocess"
exit $RESULT
fi
exec "${CLI[@]}"
else
exit $RESULT
fi
Along with wait-for-it.sh file, we will also include requirements.txt file which will contain all the dependency required by our Kafka Python Producer.
kafka-python==2.0.2
schedule==1.1.0
aiokafka==0.7.2
Faker==15.1.3
Step 5: Dockerize Kafka Python Producer
Let’s add Dockerfile for our Kafka Python Producer
From python:3.8-slim
COPY requirements.txt .
RUN set -ex; \
pip install --no-cache-dir -r requirements.txt
# Copy resources
WORKDIR /
COPY wait-for-it.sh wait-for-it.sh
ADD python-producer.py .
CMD ./wait-for-it.sh -s -t 30 $ZOOKEEPER_SERVER -- ./wait-for-it.sh -s -t 30 $KAFKA_SERVER -- python -u python-producer.py
Step 6: Setting up Apache Flink Consumer
Now, that we have our Python producer setup and periodically generating pair of (city, temperature) message, we will setup our Flink consumer which will basically consume the messages and aggregate the average temperature over the period of 1 minute.
Now, we will be requiring four main files for our usecase.
pom.xml - which will contain all the dependency required by our Main.java file.
Main.java - contain main logic regarding consuming messages, deserialize our message to Weather class, aggregate the average temperature over the period of 1 minute and then sink it to the Postgres DB.
Weather.java - Weather class file which we will use to create Weather objects based on each message that we consume.
WeatherDeserializationSchema - File contains logic to deserialize raw byte Kafka message to Weather class instance.
pom.xml
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.common.TopicPartition;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.api.common.functions.MapFunction;
import java.util.Arrays;
import java.util.HashSet;
public class Main {
static final String BROKERS = "kafka:9092";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
System.out.println("Environment created");
KafkaSource<Weather> source = KafkaSource.<Weather>builder()
.setBootstrapServers(BROKERS)
.setProperty("partition.discovery.interval.ms", "1000")
.setTopics("weather")
.setGroupId("groupdId-919292")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new WeatherDeserializationSchema())
.build();
DataStreamSource<Weather> kafka = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka");
System.out.println("Kafka source created");
DataStream<Tuple2<MyAverage, Double>> averageTemperatureStream = kafka.keyBy(myEvent -> myEvent.city)
.window(TumblingProcessingTimeWindows.of(Time.seconds(60)))
.aggregate(new AverageAggregator());
DataStream<Tuple2<String, Double>> cityAndValueStream = averageTemperatureStream
.map(new MapFunction<Tuple2<MyAverage, Double>, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(Tuple2<MyAverage, Double> input) throws Exception {
return new Tuple2<>(input.f0.city, input.f1);
}
});
System.out.println("Aggregation created");
// cityAndValueStream.print();
cityAndValueStream.addSink(JdbcSink.sink("insert into weather (city, average_temperature) values (?, ?)",
(statement, event) -> {
statement.setString(1, event.f0);
statement.setDouble(2, event.f1);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:postgresql://docker.for.mac.host.internal:5438/postgres")
.withDriverName("org.postgresql.Driver")
.withUsername("postgres")
.withPassword("postgres")
.build()
));
env.execute("Kafka-flink-postgres");
}
/**
* Aggregation function for average.
*/
public static class AverageAggregator implements AggregateFunction<Weather, MyAverage, Tuple2<MyAverage, Double>> {
@Override
public MyAverage createAccumulator() {
return new MyAverage();
}
@Override
public MyAverage add(Weather weather, MyAverage myAverage) {
//logger.debug("add({},{})", myAverage.city, myEvent);
myAverage.city = weather.city;
myAverage.count = myAverage.count + 1;
myAverage.sum = myAverage.sum + weather.temperature;
return myAverage;
}
@Override
public Tuple2<MyAverage, Double> getResult(MyAverage myAverage) {
return new Tuple2<>(myAverage, myAverage.sum / myAverage.count);
}
@Override
public MyAverage merge(MyAverage myAverage, MyAverage acc1) {
myAverage.sum = myAverage.sum + acc1.sum;
myAverage.count = myAverage.count + acc1.count;
return myAverage;
}
}
public static class MyAverage {
public String city;
public Integer count = 0;
public Double sum = 0d;
@Override
public String toString() {
return "MyAverage{" +
"city='" + city + '\'' +
", count=" + count +
", sum=" + sum +
'}';
}
}
}
Main.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.common.TopicPartition;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.api.common.functions.MapFunction;
import java.util.Arrays;
import java.util.HashSet;
public class Main {
static final String BROKERS = "kafka:9092";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
System.out.println("Environment created");
KafkaSource<Weather> source = KafkaSource.<Weather>builder()
.setBootstrapServers(BROKERS)
.setProperty("partition.discovery.interval.ms", "1000")
.setTopics("weather")
.setGroupId("groupdId-919292")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new WeatherDeserializationSchema())
.build();
DataStreamSource<Weather> kafka = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka");
System.out.println("Kafka source created");
DataStream<Tuple2<MyAverage, Double>> averageTemperatureStream = kafka.keyBy(myEvent -> myEvent.city)
.window(TumblingProcessingTimeWindows.of(Time.seconds(60)))
.aggregate(new AverageAggregator());
DataStream<Tuple2<String, Double>> cityAndValueStream = averageTemperatureStream
.map(new MapFunction<Tuple2<MyAverage, Double>, Tuple2<String, Double>>() {
@Override
public Tuple2<String, Double> map(Tuple2<MyAverage, Double> input) throws Exception {
return new Tuple2<>(input.f0.city, input.f1);
}
});
System.out.println("Aggregation created");
// cityAndValueStream.print();
cityAndValueStream.addSink(JdbcSink.sink("insert into weather (city, average_temperature) values (?, ?)",
(statement, event) -> {
statement.setString(1, event.f0);
statement.setDouble(2, event.f1);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:postgresql://docker.for.mac.host.internal:5438/postgres")
.withDriverName("org.postgresql.Driver")
.withUsername("postgres")
.withPassword("postgres")
.build()
));
env.execute("Kafka-flink-postgres");
}
/**
* Aggregation function for average.
*/
public static class AverageAggregator implements AggregateFunction<Weather, MyAverage, Tuple2<MyAverage, Double>> {
@Override
public MyAverage createAccumulator() {
return new MyAverage();
}
@Override
public MyAverage add(Weather weather, MyAverage myAverage) {
//logger.debug("add({},{})", myAverage.city, myEvent);
myAverage.city = weather.city;
myAverage.count = myAverage.count + 1;
myAverage.sum = myAverage.sum + weather.temperature;
return myAverage;
}
@Override
public Tuple2<MyAverage, Double> getResult(MyAverage myAverage) {
return new Tuple2<>(myAverage, myAverage.sum / myAverage.count);
}
@Override
public MyAverage merge(MyAverage myAverage, MyAverage acc1) {
myAverage.sum = myAverage.sum + acc1.sum;
myAverage.count = myAverage.count + acc1.count;
return myAverage;
}
}
public static class MyAverage {
public String city;
public Integer count = 0;
public Double sum = 0d;
@Override
public String toString() {
return "MyAverage{" +
"city='" + city + '\'' +
", count=" + count +
", sum=" + sum +
'}';
}
}
}
Weather.java
import java.util.Objects;
public class Weather {
/*
{
"city": "New York",
"temperature": "10.34"
}
*/
public String city;
public Double temperature;
public Weather() {}
public Weather(String city, String temperature) {
this.city = city;
this.temperature = Double.valueOf(temperature);
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("Weather{");
sb.append("city=").append(city).append('\'');
sb.append(", temperature=").append(String.valueOf(temperature)).append('\'');
return sb.toString();
}
public int hashCode() {
return Objects.hash(super.hashCode(), city, temperature);
}
}
WeatherDeserializationSchema
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.json.JsonMapper;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import java.io.IOException;
import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
public class WeatherDeserializationSchema extends AbstractDeserializationSchema<Weather> {
private static final long serialVersionUUID = 1L;
private transient ObjectMapper objectMapper;
@Override
public void open(InitializationContext context) {
objectMapper = JsonMapper.builder().build().registerModule(new JavaTimeModule());
}
@Override
public Weather deserialize(byte[] message) throws IOException {
return objectMapper.readValue(message, Weather.class);
}
}
Conclusion
Today we looked at how to build a real time data streaming pipeline using Apache Kafka, Apache Flink and Postgres.
Repository:
https://github.com/redhabayuanggara21/flinkecommerce
https://github.com/redhaanggara21/data-streaming
Reference: