

Chapters:
Service Discovery, Monitoring and Troubleshooting | Part 1
Grafana Monitoring Workflow | Part 2
Devops Workflow Troubleshooting | Part 3
Carry away Consistensy Pattern | Part 4
DevSecOps Development, Security and Operation | Part 5
Distributed Systems and Orchestration Docker And Swarm | Part 6
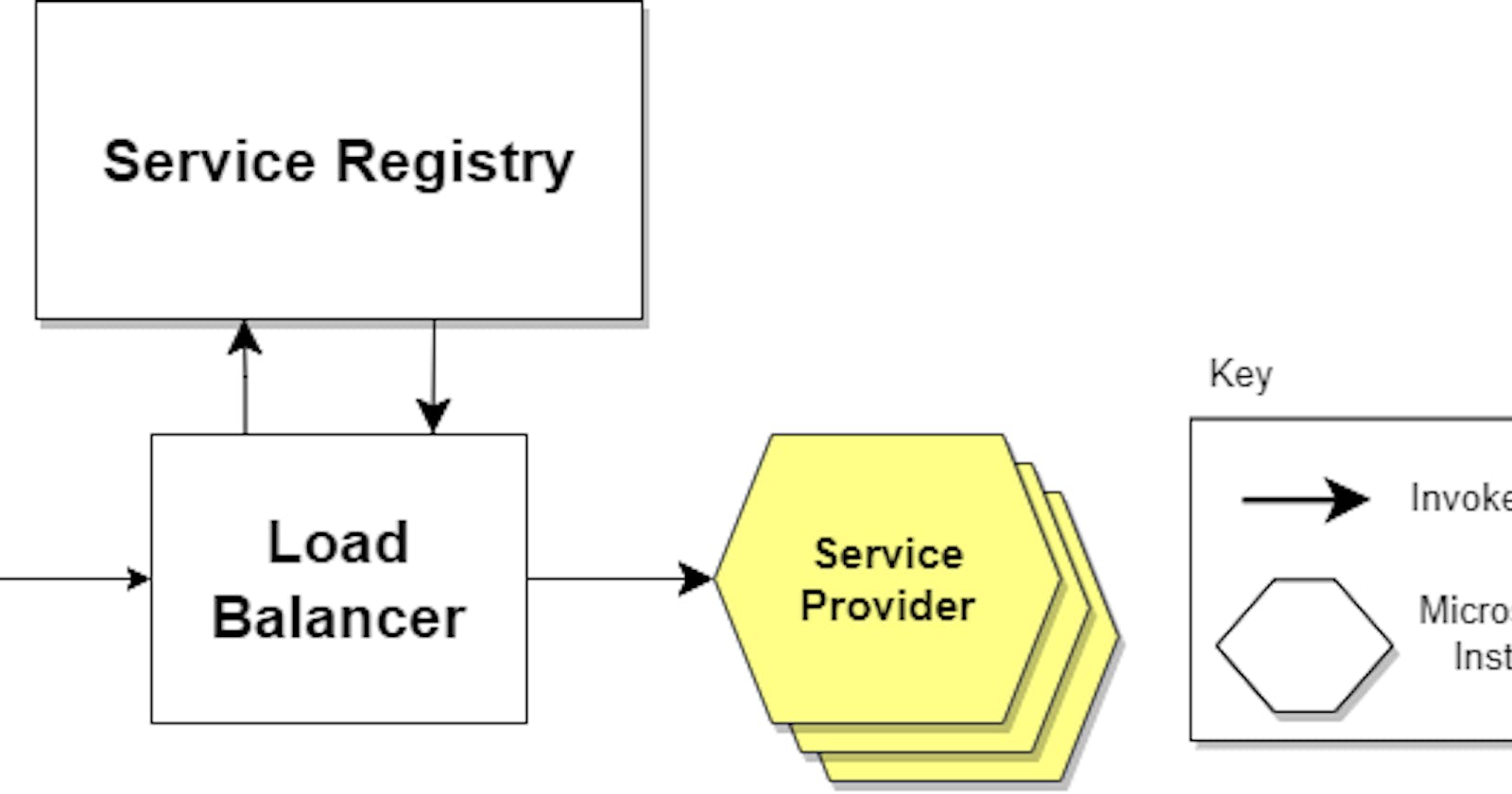
Service Discovery Workflow
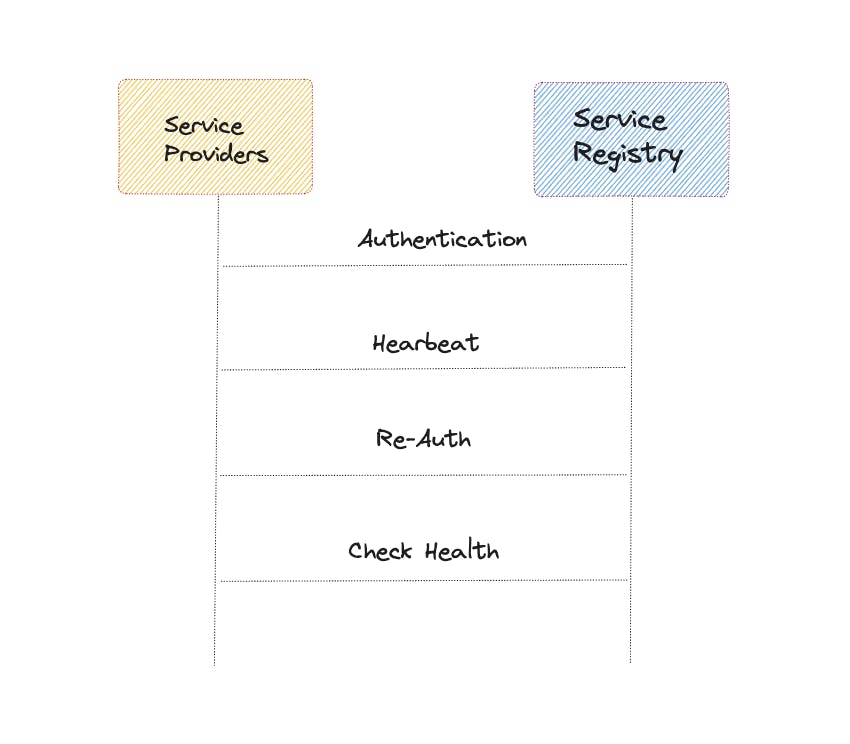
The service provider shares its IP address and port number for registration with the service registry. A periodic heartbeat signal is utilized to indicate the current status of a service instance.
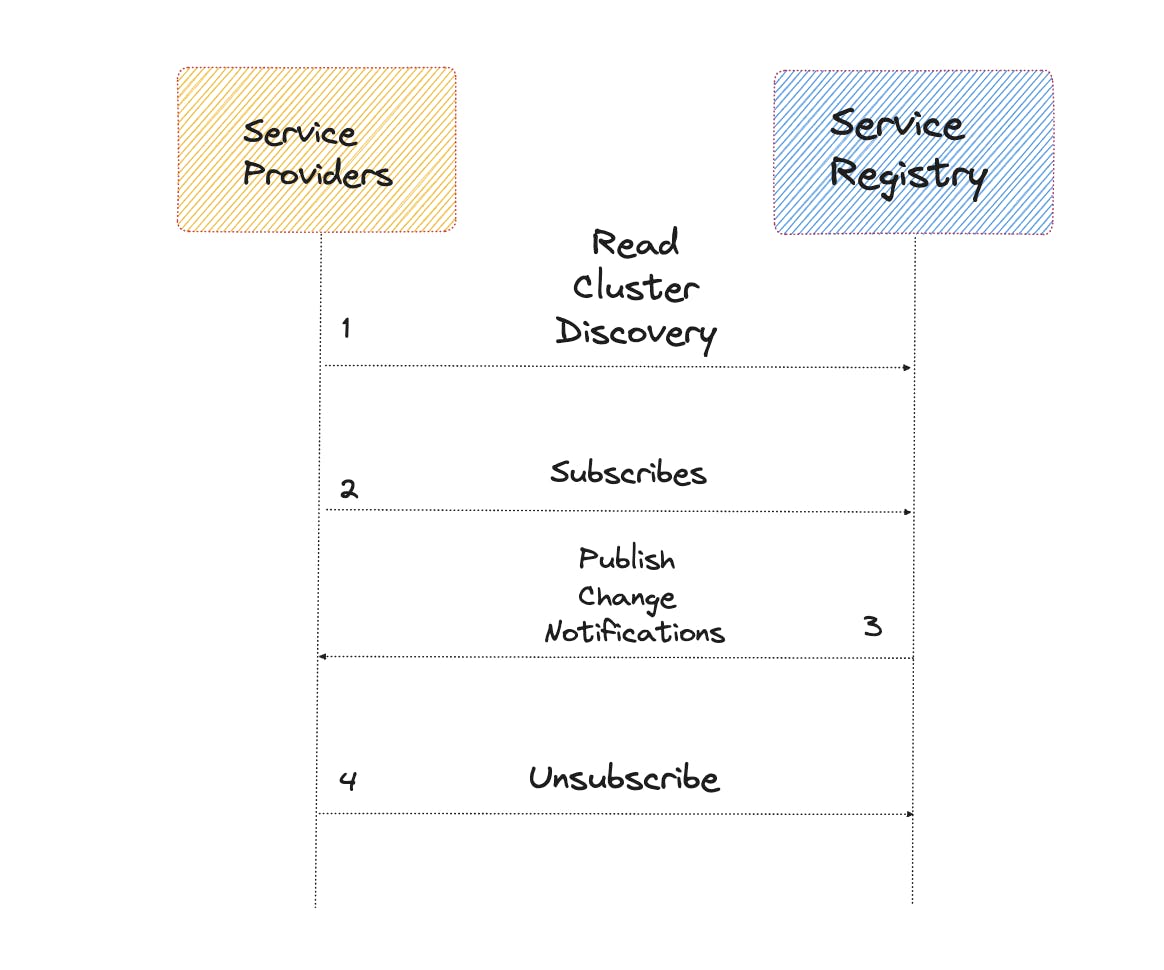
By users the publish-subscribe pattern, reliable service discovery can be implemented. In this approach, service consumers are advised to subscribe to the desired service providers listed in the service registry. As any modifications occur in the service providers, the service registry proactively notifies the subscribed service consumers of these changes.
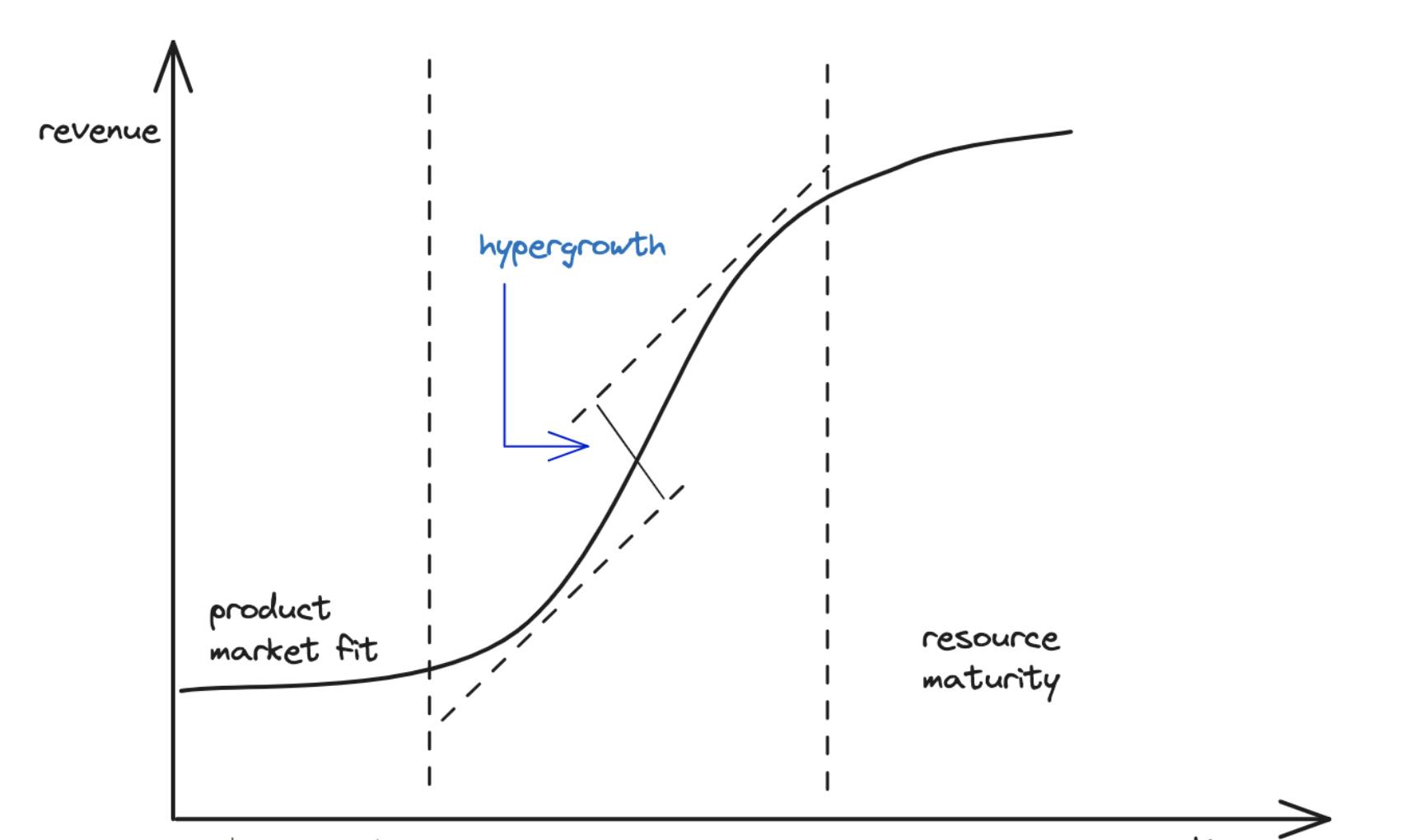
Hyperscale
Hypergrowth occurs when growth exceeds the expected level by more than 40%. Yet most companies with hypergrowth fail due to scalability problems.
So they need to hyperscale.
Hyperscale is the architecture’s ability to scale quickly based on the changing demand. It needs extreme parallelization and fault isolation.
So he was frustrated.
Titanic’s Designer Talking About Its Resilience
Until one weekend he watches the film Titanic on television.
The scene in which the ship’s designer talks about its resilience caught his attention.
Vertical Partition Walls Dividing the Ship’s Interior Into Watertight Compartments
They partitioned the ship's interior using vertical walls. Thus compartments become water-tight and self-contained. And the ship wouldn't sink unless many compartments were affected.
Pointer (Featured)
If you find system design useful, consider checking out Pointer.io. It’s a reading club for software developers read by CTOs, engineering managers, and senior developers. They send out super high-quality engineering-related content and it’s completely free!
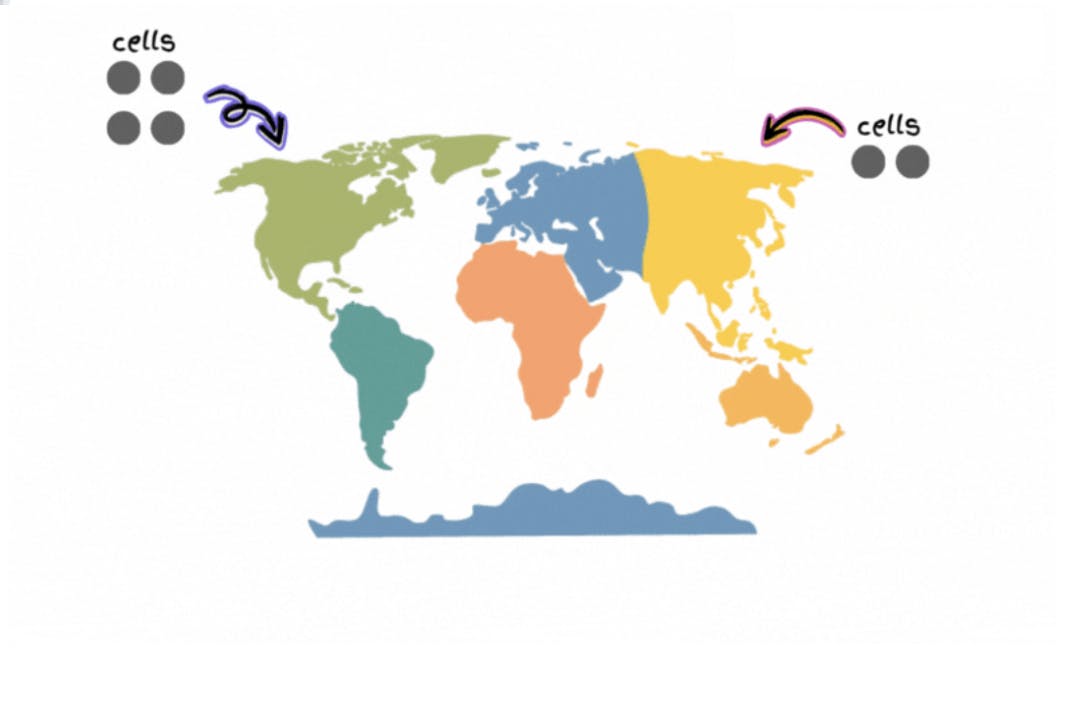
Cell Based Architecture
Here’s how cell based architecture works:
1. Implementation
A system is divided into cells and the traffic gets routed between the cells using a cell router.
A cell might contain many services, load balancers, and databases. And it’s technology-agnostic.
Put another way, a cell is a completely self-contained instance of the application. So it’s independently deployable and observable.
The customer traffic gets routed to the right cells via a thin layer called the
Cell router.
Cell Based Architecture
The failure of a cell doesn’t affect another one because they are separated at the logical level. In other words, cell based architecture prevents single points of failure.
A cell could be created using an infrastructure as a code script or any programming language. While each cell gets a name and a version identifier.
The components within a cell communicate with each other through supported network mechanisms. While external communication happens on standard network protocols via a gateway.
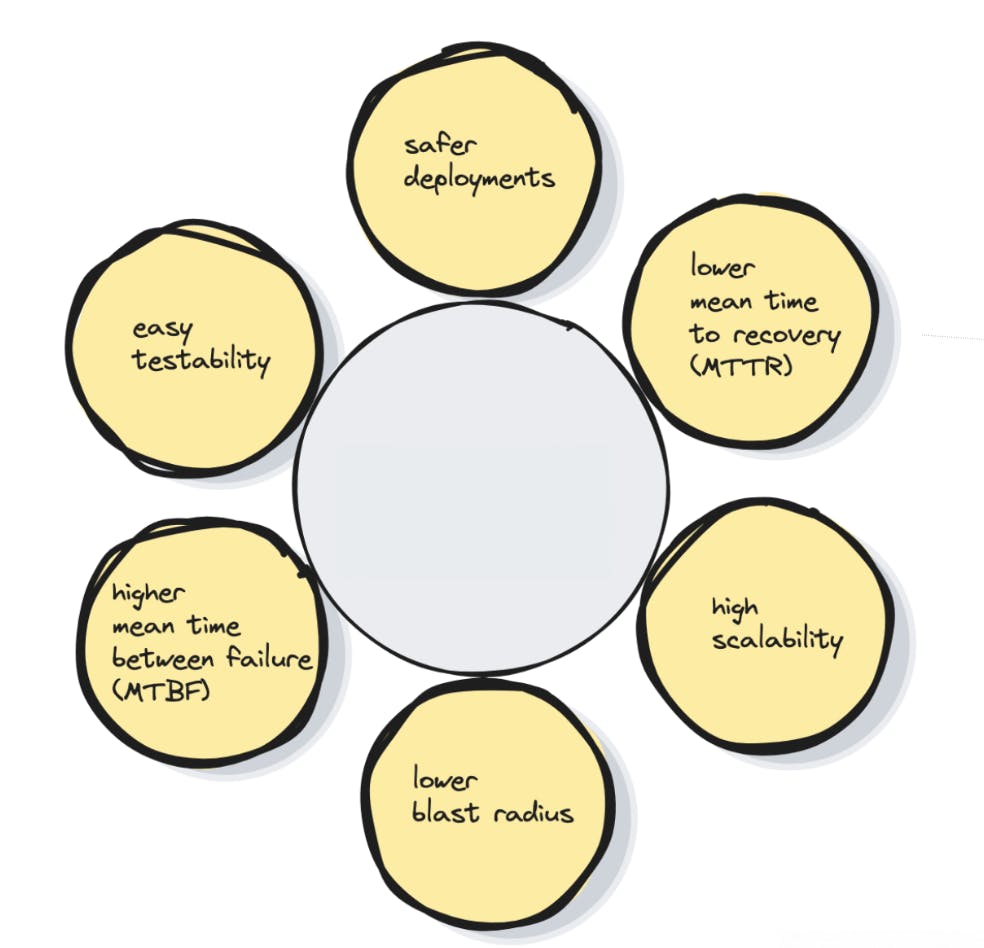
Reducing Scope of Impact With Cell Based Architecture, A cell shouldn’t share its state with others and handle only a subset of the total traffic. Thus the impact of a failure like a bad code deployment is reduced.
If a cell fails, only the customers in that specific cell are affected. So the blast radius is lower.
Put another way, if a system contains 10 cells and serves 100 requests. The failure of a single cell affects only 10% of requests.
Blast radius is the approximate number of customers affected by a failure.
2. Key Concepts
Here are some key concepts of cell based architecture:
a) Customer Placement
The cells get partitioned using a partition key. A simple or composite partition key can be used to distribute the traffic between cells.
And the Customer ID is a
candidate partition key for most use cases.
Mapping Customers to Right Cells
The cell router forwards requests to cells based on the partition key. Consistent hashing, or range-based mapping algorithms can be used to map customers to cells.
Provisioning Cells Based on the Number of Customers
The number of customers supported by a specific cell depends on its capacity. And a service can be scaled out by adding more cells.
b) Cell Router
A simple router can be implemented with a DNS. While an API gateway and a NoSQL database like DynamoDB can be used for complex routing.
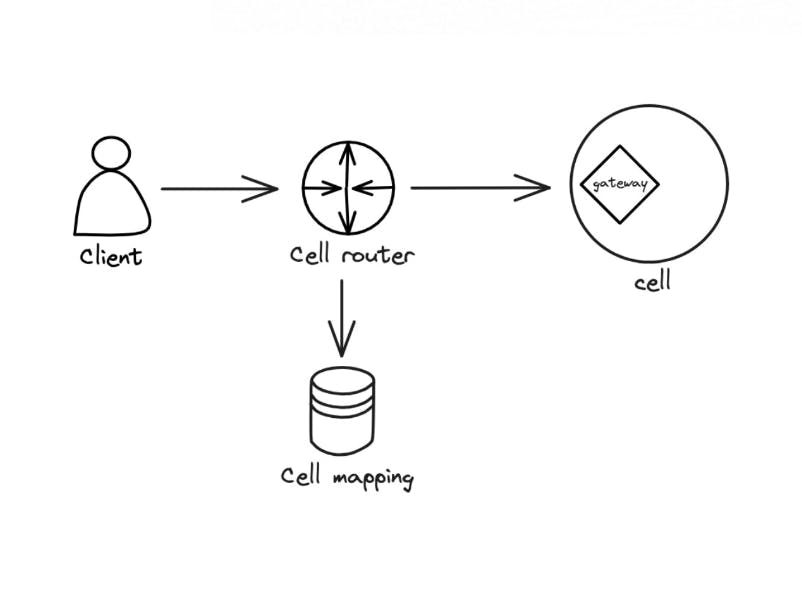
The routing layer must be kept simple and horizontally scalable to prevent failures.
Routing Traffic to the Right Cell
A dedicated gateway can be installed on each cell for communication. And it becomes the single access point to the cell. Alternatively a shared gateway can be set up via a centralized deployment.
The gateway provides a well-defined interface to a subset of APIs, events, or streams.
c) Cell Size
Each cell must have a fixed maximum size. Thus the risk of non-linear scaling factors and contention points gets reduced.
Also scaling out and stress testing is easier with fixed-size cells. So the mean time between failures (MTBF) is higher.
And the number of hosts that need to be touched for deployments and diagnosis is reduced. So the mean time to recovery (MTTR) is lower.
Yet the cell boundary depends on the business domain and organizational structure
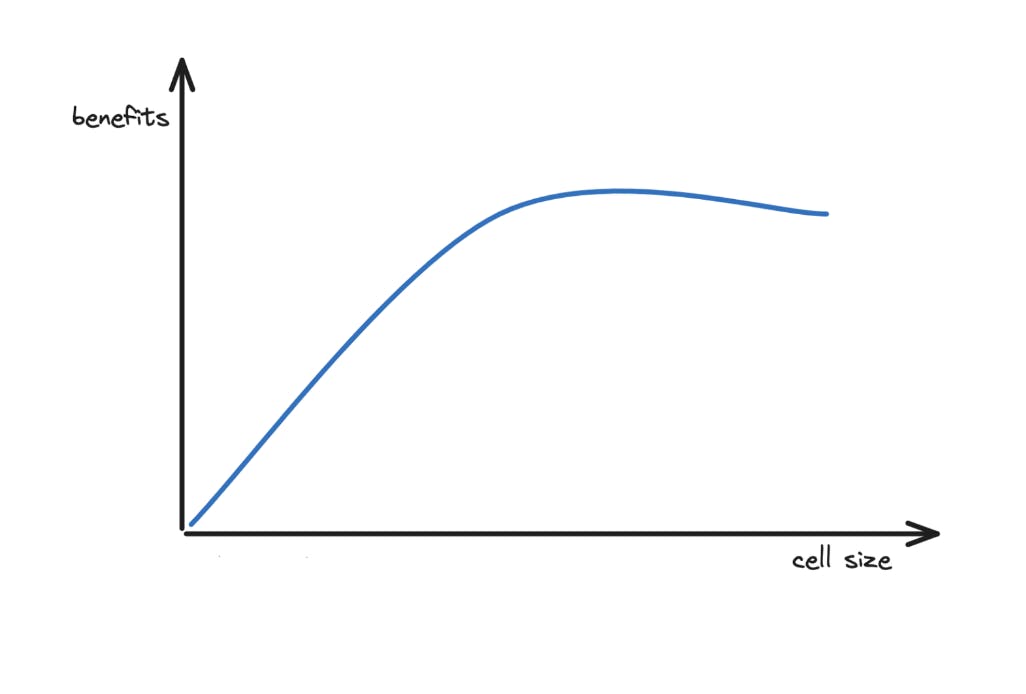
.
Cell Size vs Benefits
The blast radius is smaller when there are many small cells. Yet capacity is better used with a few large cells. So an optimal cell size must be chosen for best performance.
d) Cell Deployment
A deployment must be tested on a single cell before rolling it to others for safety.
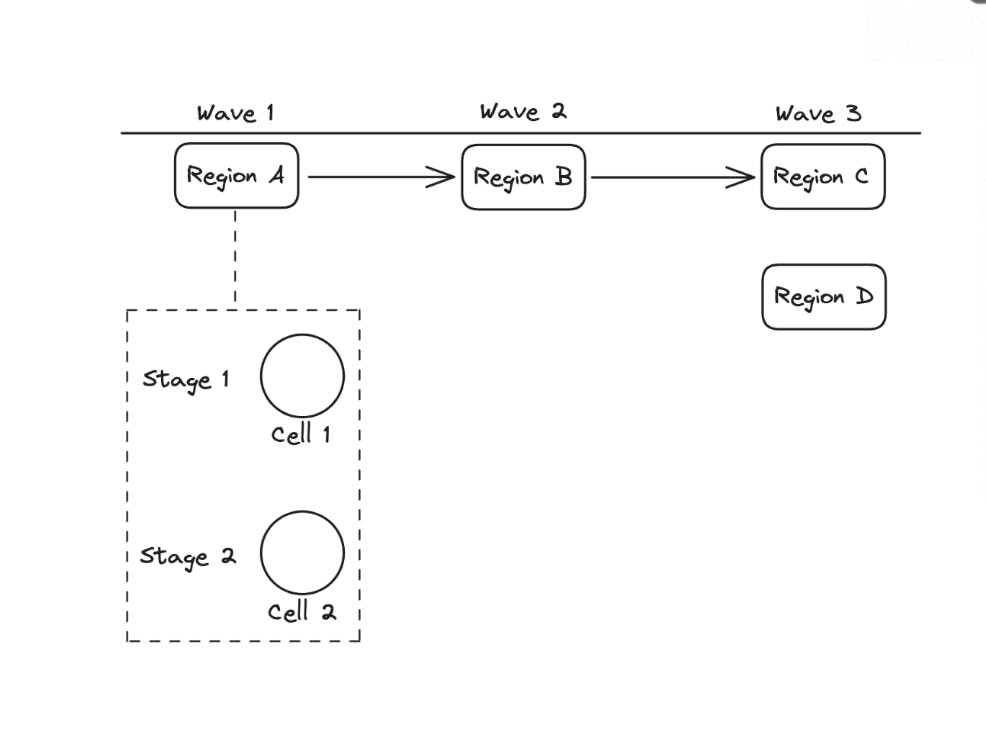
Cell Deployment in Waves
So the cells get deployed in waves and the metrics are monitored. A deployment is rolled back if there is a failure and a new wave gets introduced.
3. Use Cases
Some use cases where cell based architecture is a good fit are:
Applications that need high availability
High-scale systems that are too big to fail
Systems with many combinations of test cases but insufficient coverage
The cell boundaries provide resilience against failures like buggy feature deployments. And it avoids poison pill requests by limiting the scope of impact.
Resilience is the ability of the system to recover from a failure quickly.
A poison pill request occurs when a request triggers a failure mode across the system.
Benefits of Cell Based Architecture
The cell based architecture makes the design more modular and reduces failover problems.
Besides issues due to misbehaving clients, data corruption, and operational mistakes gets prevented.
4. Best Practices
Here’s a list of best practices with cell based architecture:
Start with more than a single cell from day 1 to get familiar with the architecture
Consider the current tech stack as cell zero and add a router layer
Perform a failure mode analysis of the cell to find its resilience
A single team could own an entire cell for simplicity. But with cell boundary on the bounded context
Cells should communicate via versioned and well-defined APIs
Cells must be secured through policies in API gateways
Cells should throttle and scale independently
The dependencies between cells reduce the benefits of cell based architecture. So they should be kept minimum
There shouldn’t be shared resources like databases to avoid a global state
The cells should get deployed in waves
5. Anti-Patterns
Here’s a list of common anti-patterns with cell based architecture:
Growing the cell size without limits
Deploying code to every cell at once
Sharing state between cells
Adding complex logic to the routing layer
Increased interactions between cells
6. Cell Based Architecture vs Microservices
A cell could represent a bounded context. And it can be implemented as a monolith, a set of microservices, or serverless functions.
Bounded Context in Domain-Driven Design (DDD) is the explicit domain model boundary.
Repository: